Seit in vielen Verlagen neben jedem Kopierer ein XML-Konverter steht, lassen sich barrierefreie E-Books leicht und schnell erstellen – solange man Bilder ausklammert. Denn damit ein Bildmotiv für einen Menschen mit Sehbehinderung zugänglich wird, braucht es Alternativtexte und gerade die fehlen leider in vielen E-Books. Doch wie gelangt man zu vernünftigen Alternativtexten und wie lassen sich diese durch den Prozess schleusen?
Alternativtexte sollten möglichst deskriptiv beschreiben, was auf dem Bild zu sehen ist. Warum dafür die Zweitverwertung der Bildlegende nicht ausreicht, hat Elena Natario in ihrem Blogartikel Alt vs Figcaption schön erklärt.
Alternativtexte muss also irgendjemand schreiben, die eigentlich interessante Frage ist nur wer? Bestenfalls ist das schon geschehen, weil etwa die Bildagentur die Alternativtexte in den Metadaten schon liefert. Falls nicht, muss man diese Aufgabe jemandem aufdrücken, z.B. Autoren, Lektoraten oder einer „künstlichen Intelligenz“ (KI). Autoren und Lektoren genießen qua Berufsbeschreibung die inhaltliche Deutungshoheit im Verlag und bieten sich daher auch als Verfasser von Alternativtexten an. Autoren und Lektoren haben aber chronisch keine Zeit, weshalb es charmant erscheint, die Arbeit einfach einer KI zu überlassen.
Aus diesem Grund habe mir mal Microsofts Azure Computer Vision API angeschaut und sie mit ein paar Bildern gefüttert. So schlug Azure Computer Vision zu einem Foto einer Schafherde passend „a herd of sheep standing on top of a grass covered field“ vor. Das Foodporn-Bild einer Bockwurst wurde immerhin noch als „hot dog“ interpretiert. Das Foto einer Zeitung beschrieb die KI jedoch nur noch wortkarg mit „letter, text“. Natürlich konnte ich der KI auch Bilder nicht ersparen, die schon wir Menschen sehr schwer aushalten.
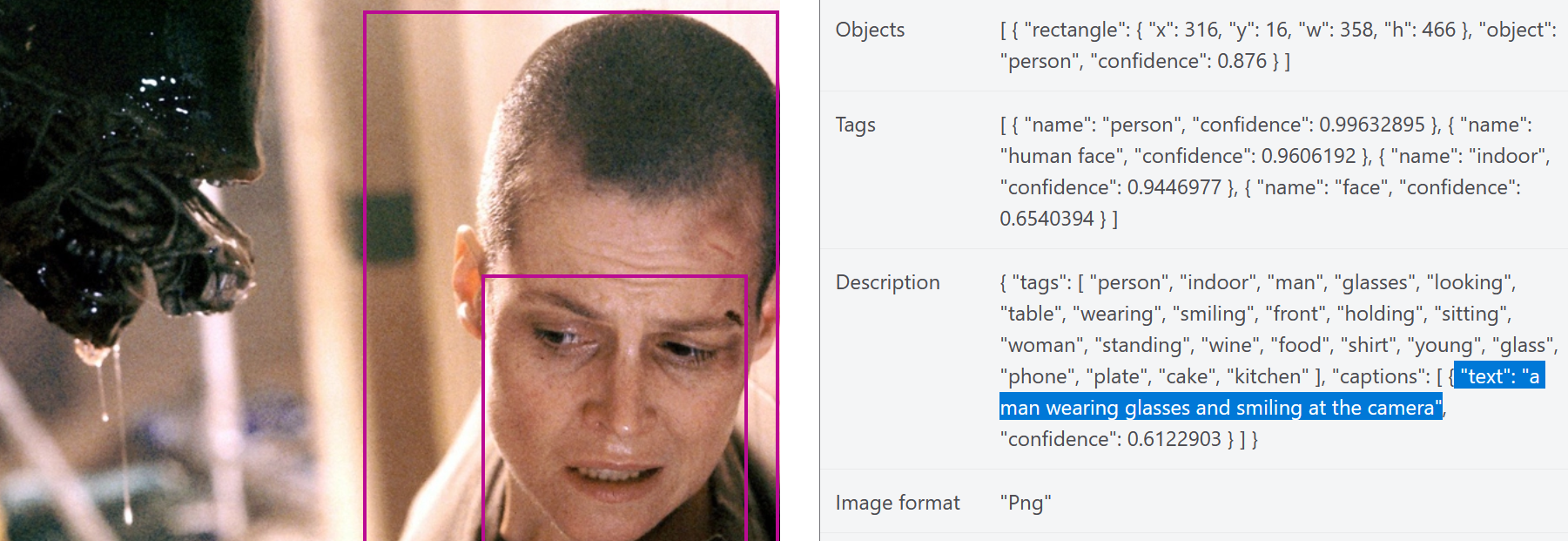
Während die Tags „plate“, „cake“ und „kitchen“ vielleicht noch gut die Gedanken des Aliens widerspiegeln, so wird die Beschreibung „a man wearing glasses and smiling at the camera“ hier den Umständen der Szene aus Alien 3 nicht ganz gerecht. Es ist auch nicht klar, ob es an den kurzen Haaren liegt oder die KI von Männern trainiert wurde, aber es scheint ein gewisser Gender Bias durch, wenn Frau Ripley hier von der KI als „Mann“ gelesen wird.
Das Beispiel zeigt mithin, dass für die Erkennung bestimmter Bilder eine KI allein keine zuverlässige Methode darstellt. Allerdings wäre vorstellbar, dass sie wenigstens eine Unterstützung für die Verfassung von Alternativtexten darstellt. Stand jetzt werden Menschen aber wohl erstmal weiterhin die Verantwortung für Alternativtexte tragen müssen.
Liegen die Alternativtexte einmal vor, stellt sich die Frage, wo man sie speichert und im Prozess weiterreicht. Der Alternativtext ist ein Metadatum des Bildes und daher bieten sich natürlich zuerst die Metadaten in der Bilddatei selbst zur Speicherung an. Für TIFF- und JPEG-Dateien gibt es z.B. den IPTC-Standard der für Alternativtexte das Metadatum description vorsieht. Mit vielen Bildbearbeitungsprogrammen wie Photoshop oder Gimp kann man Alternativtexte direkt in der Datei kodieren was auch die lästige Frage erübrigt, wo man sie sonst speichern möchte.
Mit InDesign kann man diese Bild-Metadaten sogar via Skript einfach auslesen. Hier ist mal ein Beispiel, welches die Alternativtexte aller Verknüpfungen im aktiven Dokument in ein Array speichert.
var doc = app.documents[0];
var links = doc.links;
var altTexts = [];
for (var i = 0; i < links.length; i++) {
altTexts[i] = links[i].linkXmp.description
}Außerdem kann man in InDesign auch selbst Alternativtexte eingeben. Das geschieht über die Objektexportoptionen, welche man gleichsam durch Scripting auslesen kann.
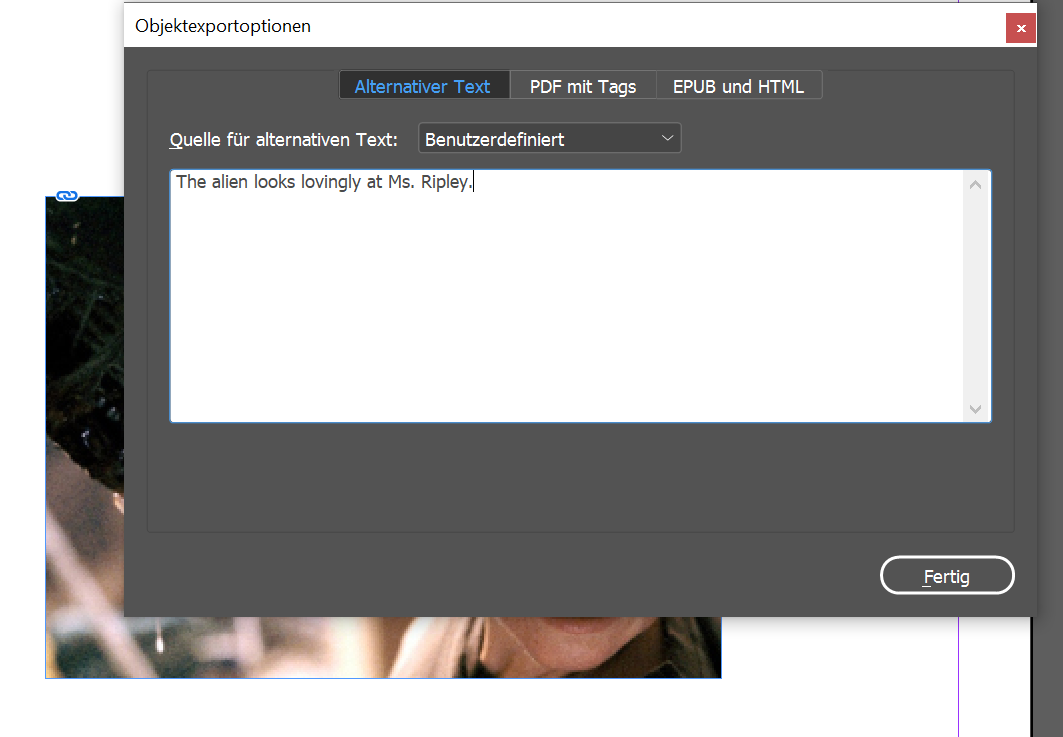
In diesem Sinne habe ich mein Bildexportskript so erweitert, dass es Alternativtexte in versteckte Labels speichert, die sich später beim IDML-Export aus der IDML auslesen lassen (Code wurde aus Gründen der Lesbarkeit gekürzt):
<Rectangle>
<Properties>
<Label>
<KeyValuePair Key="letex:fileName" Value="sigourney.jpg" />
<KeyValuePair Key="letex:altText" Value="The alien looks lovingly at Ms. Ripley." />
</Label>
<!-- (...) -->
</Rectangle>
Nun kann man den Alternativtext auch leicht nach XML und von dort aus nach HTML und EPUB konvertieren. Für Microsoft Word ist mir hingegen kein Weg geläufig, wie man via Scripting Metadaten aus Bildern auslesen kann. Allerdings lassen sich dort zumindest Alternativtexte manuell eingeben, wobei man auch durch eine mehr oder minder hilfreiche KI unterstützt wird. Da Microsofts Azure Computer Vision eigentlich bessere Ergebnisse für dieselben Bilder liefert, wird hier scheinbar eine andere KI eingesetzt. Aber vermutlich ist Microsoft einfach ein zu großer Laden, als dass die linke Hand noch weiß was die rechte tut.
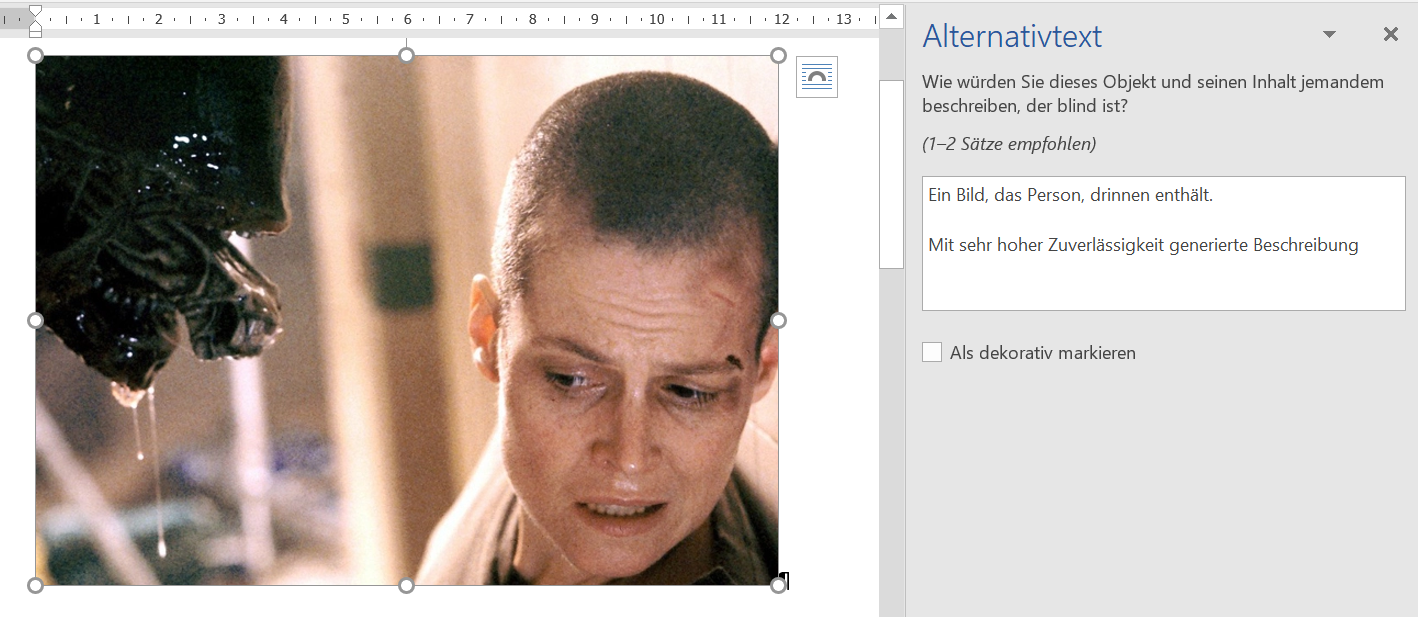
In der document.xml von OfficeOpen XML wird der Alternativtext jedenfalls im descr-Attribut von <wp:docPr/> gespeichert:
<w:drawing>
<wp:inline distT="0" distB="0" distL="0" distR="0">
<wp:extent cx="4292821" cy="3060857"/>
<wp:effectExtent l="0" t="0" r="0" b="6350"/>
<wp:docPr id="1" name="Grafik 1" descr="The Alien looks lovingly at Ms. Ripley."/>
<!-- (...) -->
</w:drawing>
Standard-XML-Formate wie DocBook, JATS und TEI bieten natürlich auch Elemente oder Attribute zur Speicherung von Alternativtexten. Hier sei nur der Kürze halber auf deren frei zugängliche Dokumentationen verwiesen. Bei der Erstellung von barrierefreien PDFs („tagged PDF“) nach dem PDF/A-1a-Standard aus Word und InDesign werden bestehende Alternativtexte übrigens auch übernommen.
Bei HTML steht das etablierte alt-Attribut innerhalb des <img/>-Tags zur Verfügung. Außerdem kann man längere Beschreibungen entweder durch eine Dateireferenz oder innerhalb einer Data URI mit dem longdesc-Attribut angeben. Für rein dekorative Bilder wie Ornamente lässt man am besten den Alternativtext ganz weg, der Screenreader überspringt das Bild beim Vorlesen einfach.
Es mangelt also nicht an Möglichkeiten, Alternativtexte zu kodieren und durch eine KI unterstützt zu erstellen. Der Ball liegt nun also im Feld der Verlage, die technischen Möglichkeiten zu nutzen und Bilder zugänglicher für alle zu machen.