Die XML-Features von InDesign haben bei der Entwicklung offenbar wenig Aufmerksamkeit von Adobes Ingenieuren erfahren. Anders sind die zahlreichen Beschränkungen bei der XML-Verarbeitung mit InDesign kaum zu erklären. InDesign- und XSLT-Skripte vermögen zwar viele Lücken zu schließen, ziehen aber aufwändige Vor- und Rückkonvertierungen des mitgeführten XML nach sich. Doch welcher Eindruck ergibt sich, wenn man die Perspektive des Entwicklers verlässt und die des Setzers einnimmt?
Zunächst muss man sich bewusst machen, dass ein Satz, der nicht nur für Print, sondern auch digitale Ausgabekanäle geeignet sein soll, höhere Anforderungen an die Auszeichnung in InDesign stellt. Die Satzdatei lässt sich nicht länger nur unter rein visuellen bzw. drucktechnischen Gesichtspunkten betrachten. Während Typografie die Semantik eines Textes für den Leser visualisiert, macht XML die Semantik für eine Maschine lesbar. Damit der Leser anschließend wieder brauchbare visuelle Repräsentationen, etwa in Form eines E-Books einer Website erhält, muss die Satzdatei diese Semantik technisch abbilden.
Die technische Abbildung kann auf verschiedenen Ebenen geschehen: Formatvorlagen können über ihren Namen semantische Informationen transportieren (z. B. Überschrift 1, Zitat oder Fußnotentext). Auch bestimmte InDesign-Layoutobjekte wie Rahmen, Fußnoten, Indexeinträge und Hyperlinks können erfasst und nach XML konvertiert werden. XML-Last-Ansätze beschränken sich bei der XML-Erstellung auf diese Formatvorlagen und Layoutobjekte. Beim XML-First-Ansatz kommt noch das importierte XML hinzu, welches neben der typografischen Ebene, eine zusätzliche technische Ebene einführt.
Nach dem XML-Import wird das XML im Hintergrund mitgeführt. Die reale XML-Struktur sieht man nur, wenn man die Strukturpalette oder den Story-Editor aktiviert. Eines dieser beiden Fenster sollte man besser geöffnet lassen, da Satz und XML bei InDesign leicht ein Doppelleben führen können.
InDesign hat keine Information darüber, was ein XML-Element in einem bestimmten Kontext für eine Bedeutung besitzt. Ein einfaches Beispiel: Wenn man einen neuen Absatz mit Return erstellt, legt InDesign nicht automatisch ein neues XML-Element an, welches den Absatz repräsentiert. Stattdessen muss man den Absatz markieren und im Menü über den Eintrag Tag für Text das passende Tag auswählen. Erst mit diesem Schritt wird das XML-Element auch erstellt.*
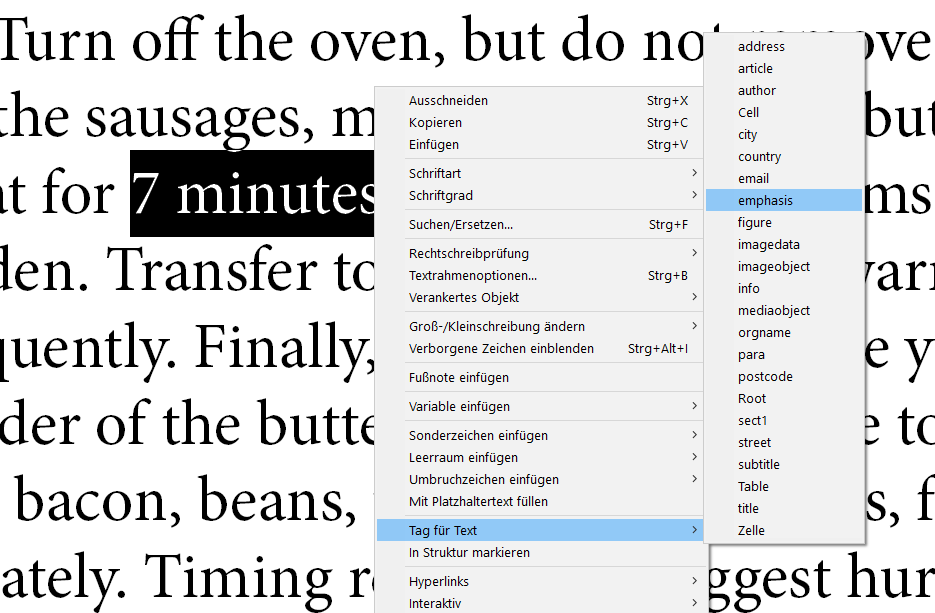
Komplizierter wird diese Prozedur, wenn mehrere Absätze von weiteren Elementen umschlossen werden, z. B. bei Kapiteln. In den meisten XML-Schemas werden die Unterkapitel eines Kapitels als dessen Kindelemente abgebildet. Übergeordnete Elemente müssen dann über die Strukturpalette erstellt werden, indem man die zu umschließenden Elemente markiert und im Kontextmenü den entsprechenden Eintrag auswählt. Dasselbe gilt auch für das Hinzufügen neuer Attribute. Die Methode, neue Elemente über das Kontextmenü hinzuzufügen ist relativ aufwändig, wenn man vergleicht wie schnell man in InDesign ein Format auf einen Absatz anwenden kann. Der Aufwand steigt also proportional zur Komplexität des XML-Schemas.
Problematisch ist auch das Löschen von Inhalten. Entfernt man einen Absatz, bleibt das zugehörige XML-Tag als leeres Tag bestehen. Damit es richtig gelöscht ist, muss man das Tag über die Strukturpalette oder den Story-Editor händisch entfernen.
Das folgende Beispiel soll dieses Problem illustrieren. Man nehme eine importierte XML-Datei mit einer Bild-Referenz. Nach dem die Daten importiert sind, möchte der Setzer ein Bild austauschen.
Der Setzer löscht das Bild, indem er den Grafikrahmen entfernt. InDesign löscht zwar das Bild, im XML wird aber nur das href-Attribut des imageobjects entfernt. Nun möchte der Setzer das Austauschbild verankern. Er geht mit dem Cursor in den Absatz, wo das alte Bild vorher verankert wurde und platziert dort das Austauschbild. Das Ergebnis: Auf der Seite ist das Bild eingebunden. Im XML hat sich seit dem Löschvorgang nichts getan. Dort steht immer noch das leere imageobject.
Würde man nach dem Austauschvorgang das XML aus InDesign exportieren, erhielte man dieses Resultat:
<mediaobject>
<imageobject/>
</mediaobject>
Wie unschwer zu erkennen ist, fehlt die Dateireferenz auf das verknüpfte Bild. Eine unbedachte Korrektur kann also schnell dazu führen, dass wichtige Strukturinformationen verloren gehen. Möchte der Setzer sauber arbeiten, muss er die Änderungen entweder zusätzlich im XML nachtragen oder das Bild über die Verknüpfungspalette austauschen.
Im Szenario eines XML-First-Workflows mit InDesign nimmt der Setzer mehr oder weniger freiwillig die Rolle eines XML-Bearbeiters an. Wenn er Fehler verursacht, können diese nicht immer mit automatischen Prüfungen aufgespürt werden. Eine Validierung bringt nur jene Fehler zum Vorschein, die gegen das XML-Schema verstoßen. Fehlen einfach „nur“ ein paar Elemente, lässt sich deren Verbleib auch nicht mit einer Schema-Validierung aufspüren.
XML und Satz können dank InDesign ein ähnlich spannungsvolles Verhältnis wie Dr. Jekyll und Mr. Hyde entwickeln. Auch wenn der Satz einen visuell einwandfreien Eindruck macht, kann die darunterliegende XML-Struktur ein anderes Gesicht zeigen. Zwar lassen sich bestimmte Fehler auch mit heuristischen Prüfungen erkennen und beheben. Skripte die auf Basis heuristischer Annahmen Daten verändern, können aber auch locker über ihr Ziel hinausschießen. Je mehr Heuristiken man verwendet, desto mehr Code braucht es, um hinterher die Scherben wegzukehren. Auch das erinnert an Jekyll und Hyde: Um sich von Hyde wieder in Jekyll zurückzuverwandeln, brauchte er schließlich immer größere Mengen seines Trankes.
↑ Zum Problem von Autorenkorrekturen bei mitgeführtem XML möchte ich auch gerne den Artikel XML-first-Workflows in InDesign: trügerische Sicherheit? von Gerrit Imsieke empfehlen. Der Beitrag ist fast fünf Jahre alt, aber dank Adobes Untätigkeit immer noch aktuell.