EPUB sei als Format besonders gut für die Produktion barrierefreier E-Books geeignet. Dabei bieten viele EPUBs auf dem Markt nicht nur keine besondere Unterstützung für Blinde und Sehbehinderte, sondern legen ihnen noch zusätzliche Steine in den Weg.
Das EPUB-Format
Dies beginnt schon beim EPUB-Format. Die meisten auf dem Markt erhältlichen E-Books sind immer noch im alten EPUB2-Format. Im Gegensatz zu seinen Nachfolger EPUB3 lässt das Format viele Accessibility-Features schmerzlich vermissen. Schuld daran ist vor allem eine Henne-Ei-Situation. Solange nicht mehr EPUB-Reader das neue Format unterstützen, setzen Verlage aus Kompatibilitätsgründen lieber auf EPUB2. Umgekehrt verspüren die Hersteller von EPUB-Readern wenig Druck, ihre alten Geräte fit für EPUB3 zu machen. Daher laufen viele Reader mit EPUB3 ähnlich gut, wie ein fußlahmes Pony auf einer Galopprennbahn.
Dabei kann man schon mit InDesign CC relativ einfach ein EPUB3 aus den Satzdaten konvertieren. Jedoch verfügt man nicht über die volle Kontrolle über das Endergebnis und die Konvertierung nimmt sich aufwändig aus: Erst müssen die Satzdaten geputzt werden (Textrahmen verketten, Bilder verankern, Formate zuweisen etc.), dann erfolgt die Konvertierung direkt aus InDesign oder mit dem Zwischenschritt HTML. Nicht selten muss anschließend im HTML- und CSS-Code nachgebessert werden, die finale Korrektur nicht zu vergessen. Am Ende drücken alle die Daumen, dass das E-Book nicht fünf Jahre später neu ausgeliefert werden muss. Aufgrund dieser vielen individuellen Einzelschritte ähnelt die Code-Produktion dem Weben des Garns in einer englischen Manufaktur des 18. Jahrhunderts.
Zusätzliche Formate oder Nachkonvertierungen erzeugen in einem so kleinteiligen Prozess hohe Aufwände. Hier werden die Vorteile einer standardisierten Produktion auf der Basis von XML deutlich. Technische Parameter können global eingestellt werden und auch ältere Titel lassen sich sauber aus XML neu nach EPUB konvertieren. Bugs wirken sich übrigens auch global aus, allerdings muss man diese auch nur an einer Stelle fixen.
Ausgezeichneter Code
Würde man sich einen Text ohne Weißraum, Schriftgrade und Schriftschnitte vorstellen, würde das mutmaßlich die Erfahrung widerspiegeln, die Sehbehinderten mit manchen E-Books bereitet wird. Das Geheimnis „barrierefreier Typografie“ liegt dagegen vor allem in gut ausgezeichnetem HTML-Code.
HTML bietet bereits eine Reihe von Tags, die von Haus aus eine bestimmte Bedeutung transportieren. Daher sollte man rein typografische Hervorhebungen mit CSS vermeiden, wenn für den Kontext nicht ein HTML-Element den besseren Job macht. Für ein Zitat ist das Tag blockquote barrierefreier, als eine Kursivstellung.
Auch die HTML-Elemente span und div sollte man nur verwenden, wenn kein besseres Tag zur Verfügung steht. Gemäß HTML-Standard tragen sie keine besondere Bedeutung („no special meaning“) und sind eher als Anker für Layoutanweisungen und Skripte gedacht:
Authors are strongly encouraged to view the div element as an element of last resort, for when no other element is suitable. Use of more appropriate elements instead of the div element leads to better accessibility for readers and easier maintainability for authors.*
So spricht die synthetische Stimme eines Screenreaders Text innerhalb eines em im Gegensatz zu span mit Betonung oder Nennung des Tags. Gegenüber span sind die Elemente strong und em die bessere Wahl.
<span class="kursiv">hervorgehoben</span><!-- falsch -->
<em>hervorgehoben</em><!-- richtig -->
Mit EPUB3 und HTML5 kommen weitere semantische Elemente hinzu: Zur Abbildung von Textabschnitten ist section besser als div geeignet und für Textblöcke außerhalb des Hauptleseflusses (z. B. Marginalien und Fußnoten) ist das Element aside angemessener.
Überschriften verschiedener Ordnungen lassen sich mit h1 bis h6 auszeichnen. Hier sollte man Hierarchiesprünge möglichst vermeiden und die Tags entsprechend ihres Grades einsetzen. Eine Überschrift erster Ebene würde man h1, für die zweite Ebene h2 usw. verwenden. Bei Abschnitten ohne Überschrift sollte man ein leeres Tag setzen und die Bedeutung in das title-Attribut schreiben.
<h1 title="Vorwort"></h1>Leider erzeugt InDesign bei der EPUB-Konvertierung zunächst wenig semantischen HTML-Code. Textrahmen, Absätze und Zeichenformaten werden mit div, p und span abgebildet. Der Name des Formats landet im Attribut @class. Die gute Nachricht ist, dass man im Menü Tagexport zumindest Absatz- und Zeichenformaten individuelle HTML-Tags zuweisen kann. Die schlechte Nachricht ist, dass die richtige Zuordnung bei jedem einzelnen Titel aufwändig, schwer kontrollierbar und damit fehleranfällig ist.
Im Rahmen eines XML-Workflows konvertiert man üblicherweise das EPUB direkt aus XML heraus. Ein XML-Schema und diverse in Schematron formulierte Prüfregeln können sicherstellen, dass etwa die Überschriftenhierarchie im Satz auch eingehalten wurde. Auch wenn im Satz nur manuelle Auszeichnungen wie halbfett und kursiv verwendet wurden, kann man diese zumindest im IDML erkennen, als Fehler ankreiden oder geräuschlos in die richtigen Tags konvertieren.
Noch mehr Semantik: epub:type-Attribute
Auch wenn HTML schon etwas Semantik bietet, so erreicht man bei vielen Büchern schnell die Grenzen. Bereits für vermeintlich einfache Dinge wie die Auszeichnung von Titelei und Vorwort ist das Vokabular von HTML zu schlicht. Mit class-Attributen kann man den HTML-Code zwar deskriptiver auszeichnen, allerdings können dort willkürliche Werte eingetragen werden, mit denen ein Lesesystemen nicht viel anzufangen weiß.
Um diesen Mangel zu beheben, wurde mit EPUB3 das Structural Semantics Vocabulary eingeführt. Unterm Strich handelt es sich dabei um einen Wortschatz für die Bezeichnung gebräuchlicher Buchinhalte. Für diese Entitäten wurden feste Codes wie z. B. preface, dedication oder colophon definiert. Ähnlich wie bei O’Reilly’s HTMLBook, werden diese Codes als HTML-Attribut an ein HTML-Element gehängt und führen so eine weitere semantische Ebene ein.
Der Sinn dieser Attribute erschließt sich vor allem bei Elementen, welche die logische Lesereihenfolge unterbrechen. Damit Fußnoten, Marginalien und Bilder beim Vorlesen von der primären Lesereihenfolge getrennt werden, sollte man sie mit einem aside-Tag (oder figure bei Bildern) und einem epub:type-Attribut auszeichnen.
<p>
Hier ist ein bisschen
Text<sup><a href="#fn-001" epub:type="noteref">1</a></sup>.
</p>
...
<aside id="fn-001" epub:type="footnote">
<p>Und hier die Fußnote</p>
</aside>ARIA-Attribute für Widgets
Nicht mal in Promille ließe sich die Anzahl von EPUBs mit interaktiven Funktionen messen. Dennoch gibt es auch Wege die Benutzeroberfläche und Funktionsweise von JavaScript-basierten Widgets zugänglicher für assistive Technologien zu gestalten. Für eine bessere Barrierefreiheit solcher Anwendungen wurde von der Web Accessibility Initiative (WAI) eine W3C Recommendation über Accessible Rich Internet Applications (ARIA) entwickelt.
ARIA ist verkürzt gesagt eine Taxonomie von Rollen, Attributen und festgelegten Werten, die man wie epub:type-Attribute an HTML-Elemente anheften kann. Im Unterschied zu epub:type-Attributen gibt ein ARIA-Attribut aber nicht nur Auskunft über die Art eines Elements. Mit ARIA kann man auch den Zustand eines Elements oder die Beziehung zu anderen Elementen ausdrücken. So lässt sich etwa mit ARIA beschreiben, ob ein Button gedrückt ist, welches Element den Button beschreibt und welches Element durch das Drücken des Buttons verändert wird.
<ul>
<li role="button" aria-labelledby="btn-desc"
aria-pressed="true" aria-controls="toggle-color">
<p id="btn-desc">
Klicke um die Farbe im Absatz unten zu ändern!
</p>
<img src="button.png" role="presentation" alt="button"/>
</li>
</ul>
<p id="toggle-color">Farbiger Text</p>
Welche EPUB-Reader unterstützen bisher ARIA-Attribute? Bei handelsüblichen Lesegeräten wie Tolino, Kobo und Co. sollte man keine falschen Erwartungen hegen. Bei Browser-basierten Plugins wie Readium für Chrome dürfte die Hoffnung größer sein, da man hier die weitaus fortgeschrittene Engine des Browsers verwendet. Da der Standard noch sehr jung ist, sollte man möglichst einen aktuellen Web-Browser nutzen und sich informieren, welche Features die Browser unterstützen.
Semantik aus dem Satz
Wie schleust man nun die ganzen Attribute in das HTML? Das Brot- und Butter-Satzprogramm InDesign bietet in CC 2015 durchaus die Möglichkeit zum Setzen von epub:type-Attributen. Für bestimmte eindeutige Typen wie Navigation und Fußnoten werden automatisch Attribute beim EPUB-Export eingefügt. Für alles andere muss man InDesigns Objektexportoptionen bemühen.
Dort findet sich ein Input-Feld, dass man in der deutschen Version schnörkellos von epub:type in EPUB:Schrift übersetzt hat. Ebenfalls ein Übersetzungsfehler scheint Adobe in der InDesign-Hilfe unterlaufen zu sein: Wenn man auf das Pfeilsymbol klickt, ändert man nicht zwangsläufig die Lesereihenfolge, wenn man einem Rahmen mit dem Structural Semantics Vocabulary taggt.
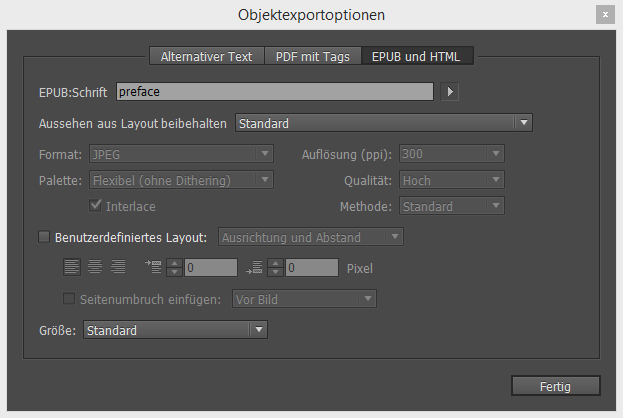
epub:type-Attributen in den Objektexportoptionen in Adobe InDesignObjektexportoptionen gelten aber nur für Rahmen, mithin muss alles, was ein epub:type-Attribute tragen soll, einen separaten Rahmen erhalten. Folglich bleiben Absatz- und Zeichenformate außen vor mit durchaus kuriosen Folgen. Möchte man Absätzen oder Zeichenketten ein epub:type-Attribut zuweisen, muss man den Text markieren, ausschneiden, in einen Rahmen kopieren, diesen wiederum mit Textumfluss an Ort und Stelle verankern und anschließend die Objektexportoption zuweisen. Es könnte nicht einfacher sein.
Weniger schmerzhaft ist es, wenn man aus XML den HTML-Code für das E-Book erzeugt. So kann man Absatz- und Zeichenformate semantisch benennen und anschließend eine IDML-Datei exportieren, die man nach XML konvertiert. Das Vokabular der meisten XML-Schemas ist wortreich genug, um daraus HTML mit entsprechenden epub:type-Attributen zu konvertieren.
Alternative Inhalte
Mit Bildern kann ein Screenreader naturgemäß nicht viel anfangen. Um deren Inhalt dennoch zugänglich zu machen, kann man alternative Beschreibungen in das alt-Attribut des img-Tags einfügen. Bestimmte Bilder sind jedoch für das Verständnis des Inhalts unwesentlich. In diesem Sinne machen Fotos dem Betrachter eines Kochbuchs vielleicht den Kauf, nicht zwingend aber das Essen schmackhafter. Bilder mit rein dekorativen Charakter kann man mit dem HTML5-Attribut role kennzeichnen und das alt-Attribut leer lassen.
<!-- wichtig -->
<img src="campbells-tomato-soup.jpg"
alt="Eine rot-weiße Konservendose mit
der Aufschrift Campbell’s tomato soup"/>
<!-- unwichtig -->
<img src="aldusblatt.jpg"
alt=""
role="presentation"/>
SVG enthält bereits einige Features, die es barrierefreier als andere Grafikformate machen. So kann man mit den Elementen title und desc Titel und Beschreibungen hinterlegen. Mit dem text-Element ausgezeichnete Textschnipsel im Bild werden als regulärer Text behandelt und können vom Screenreader dadurch vorgelesen werden.
InDesign erlaubt über die Objektexportoptionen die Eingabe von Alternativtext für Bilder. Dieser wird beim HTML-Export von InDesign berücksichtigt und selbstverständlich findet man diese Informationen auch in einer IDML-Datei.
Dennoch kann die Eingabe von Alternativtexten bei manchen Werken sehr aufwändig geraten. In den meisten Prozessen ist sie schlichtweg nicht vorgesehen. Zu klären wäre auch, wer die Alternativtexte eigentlich verfassen soll? Soll sich der Setzer etwas aus den Fingern saugen, handelt es sich um eine Aufgabe des Lektorats oder gebührt die Deutungshoheit allein dem Autor?
Formeln und Tabellen
Auch der beste Alternativtext wäre nutzlos, wenn Formeln und Tabellen als Bilder gerastert werden. Diese Technik war notwendig, um auf manchem Reader überhaupt eine halbwegs akzeptable Anzeige dieser Elemente zu ermöglichen. Als Bilder gerastert sind Formeln und Tabellen aber unzugänglich für assistive Technologien. Damit MathSpeak Formeln vorlesen kann, müssen diese als MathML ausgezeichnet sein. Bei Tabellen sollte man echtes HTML-Markup einem Bild vorziehen.
Allerdings ist nicht viel gewonnen, wenn man ein barrierefreies EPUB besitzt, aber Kindle, Tolino und Co. statt MathML nur Zeichensalat anzeigen. Hier wäre es pragmatischer, ein abgerüstetes EPUB2 mit Formel-Bildern und eine barrierefreie Version gleichzeitig auszuliefern. In EPUB3 kann man zudem Fallbacks definieren, wenn ein Lesesystem nicht in der Lage ist, MathML darzustellen:
<epub:switch id="mathmlSwitch">
<epub:case required-namespace="http://www.w3.org/1998/Math/MathML">
<math xmlns="http://www.w3.org/1998/Math/MathML">
<mi>a</mi>
<mo>+</mo>
<mi>b</mi>
<mo>=</mo>
<mi>c</mi>
</math>
</epub:case>
<epub:default>
<p>a + b = c</p>
</epub:default>
</epub:switch>
Zuvor muss man selbstredend über einen Satzprozess verfügen, mit dem man auch in der Lage ist, MathML zu produzieren. InDesign ist hier mangels Formeleditor nicht unbedingt zu empfehlen. Besser sollte man ein Satzsystem wählen, welches für den Satz von Formeln geeignet ist. Meistens basieren diese auf LaTeX oder implementieren ein MathType-Plugin wie Adobe FrameMaker.
Update 12.10.2016: Die epub:switch-Methode soll mit der neuen EPUB-Version 3.1 entfallen. Offenbar ist die Unterstützung von Lesesystemen zu heterogen, so dass stattdessen das altimg-Attribut des math-Elements für ein alternatives Bild verwendet werden soll.
Language Tagging
Die Einstellung der Sprache ist für assistive Technologien wesentlich, damit sie den Text korrekt erfassen und rendern, also die richtigen Braille-Zeichen oder die zur Sprache passende Stimme auswählen kann. Die Sprache kann man nicht nur global, sondern auch für einzelne Textpassagen definieren. Die globale Spracheinstellung wird in den OPF-Metadaten mittels des Elements dc:language gesetzt. Im OPF und im HTML lässt sich die Sprache mit dem Attribut xml:lang festlegen. Zusätzlich sollte man im HTML das Attribut lang verwenden, gesetzt den Fall, dass ein Lesesystem nur eines der beiden Attribute auswertet.
<html lang="de" xml:lang="de">
(…)
<p>Zum 100. Tor seines Spielers Franck Ribéry sagte
Karl-Heinz Rummenigge: „Ich ziehe meinen Hut und sage
<span lang="fr" xml:lang="fr">Champs-Élysées.</span>“</p>
</html>Wie lässt sich nun die Sprache ausgehend von Manuskript oder Satzdatei in das EPUB transportieren? Bei Word kann man die Sprache zur Rechtschreib- und Grammatikprüfung und bei InDesign das Wörterbuch für die automatische Silbentrennung festlegen. Beides lässt sich jeweils für Absatz- und Zeichenformate einstellen.
Für Word muss man die Spracheinstellung der Absatz- und Zeichenformate aus der DOCX-Datei extrahieren. Wenn man die DOCX-Datei entpackt, finden sich die Informationen in einer XML-Datei unter word/styles.xml.
<w:style w:type="paragraph" w:styleId="Normal">
<w:name w:val="Heading 1"/>
(…)
<w:lang w:val="de-DE" w:eastAsia="zh-CN" w:bidi="hi-IN"/>
</w:style>InDesign setzt beim Export von HTML und EPUB immerhin von allein xml:lang, aber leider nicht lang. Bei XML zeigt sich wieder, dass man mit IDML deutlich besser fährt, als mit XML-Import und Export („XML-First“). Beim Import von XML führt ein xml:lang-Attribute nicht zu einer entsprechenden Wörterbucheinstellung. Auch beim XML-Export wird die eingestellte Sprache ignoriert. Im Gegensatz dazu muss man bei IDML nur das Attribut AppliedLanguage auswerten, welches entweder beim Format in der Datei Resources/Styles.xml oder bei Formatüberschreibungen an Ort und Stelle angegeben wird:
<CharacterStyleRange
AppliedCharacterStyle="CharacterStyle/$ID/[No character style]"
AppliedLanguage="$ID/English: USA">
<Content>The quick brown fox jumps over the lazy dog</Content>
</CharacterStyleRange>Im erzeugten XML bilden wir bei transpect die Sprache als xml:lang-Attribut in einer CSS-Formatdeklartionen ab. Das CSS-Attribut css:direction bildet die Leserichtung ab.
<css:rule name="No_paragraph_style" xml:lang="de" css:direction="ltr" css:hyphens="auto" native-name="$ID/[No paragraph style]" layout-type="para" css:font-weight="normal" css:font-style="normal" css:font-size="12pt" css:text-transform="none" css:margin-left="0pt" css:margin-right="0pt" css:text-indent="0pt" css:margin-top="0pt" css:margin-bottom="0pt" css:text-decoration-line="none" css:text-align="left" css:font-family="Minion Pro"/>Navigation
Neben der Überschriftenhierarchie spielt das EPUB-Inhaltsverzeichnis, das sogenannte toc nav eine wichtige Rolle, damit man sich schnell durch alle Teile des E-Books navigieren kann. Grundsätzlich sollte man alle wichtigen Abschnitte in das Inhaltsverzeichnis aufnehmen. Unterkapitel, die dennoch visuell nicht erscheinen sollen, kann man mit dem hidden-Attribut ausblenden. Besteht ein Eintrag nur aus einer Formel oder einem Bild, sollte man einen Alternativtext in das title-Attribut eintragen.
<nav epub:type="toc" id="toc">
<h1>Inhaltsverzeichnis</h1>
<ol>
<li>
<a href="chap1.xhtml">Kapitel 1</a>
<-- hidden-Attribut zum Ausblenden von Inhalten im ToC -->
<ol hidden="">
<li>
<a href="chap1.xhtml#sec-1.1">Kapitel 1.1</a>
</li>
<li>
<a href="chap1.xhtml#sec-1.2">Kapitel 1.2</a>
</li>
</ol>
</li>
<li>
<-- title-Attribut mit Alternativtext -->
<a href="chap2.xhtml" title="Kapitel 2">
<img src="chap2.png"/>
</a>
</li>
(…)
</ol>
</nav>
Neben dem Inhaltsverzeichnis kann man auch ein sogenanntes landmarks nav einfügen, welches wichtige Abschnitte im Buch identifiziert und damit auch die Orientierung erleichtert. Im landmarks nav müssen alle Links mit epub:type-Attributen ausgezeichnet sein.
<nav epub:type="landmarks" hidden="">
<ol>
<li><a epub:type="cover" href="cover.xhtml">Umschlag</a></li>
<li><a epub:type="titlepage" href="titlepage.xhtml#title">Titelseite</a></li>
<li><a epub:type="preface" href="preface.xhtml#title">Vorwort</a></li>
<li><a epub:type="toc" href="toc.xhtml#TOC">Inhalt</a></li>
<li><a epub:type="bodymatter" href="chapter1.xhtml">Start of Content</a></li>
<li><a epub:type="index" href="index.xhtml">Register</a></li>
</ol>
</nav>
Für Fixed-Layout-Publikationen kann man zudem ein page-list nav anbieten. Dieses Verzeichnis besteht aus einer Liste von Seitenumbrüchen und bietet so die Möglichkeit Seitenzahlen aus der Print-Publikation zu referenzieren.
<nav epub:type="page-list" hidden="">
<ol>
<li><a href="chapter01.xhtml#page009">9</a></li>
<li><a href="chapter01.xhtml#page010">10</a></li>
<li><a href="chapter01.xhtml#page011">11</a></li>
(…)
</ol>
</nav>
Metadaten
Die Accessibility eines E-Books bestimmt sich nicht zuletzt auch durch die Kenntnis seiner Accessibility-Features. Über die Qualität der Barrierefreiheit können ONIX- und RDFa-Metadaten Auskunft geben.
ONIX ist in der Verlagsbranche ein XML-basiertes Datenformat zum Austausch von Produkt-Metadaten. Über welche Accessibility-Features ein EPUB verfügt, kann mit ONIX-Einträgen aus der Code-List
ONIX Code List 196 angegeben werden. Features wie toc nav, Alternativtexte, Language Tagging werden Codes zugeordnet und können dann wie in folgendem Beispiel abgebildet werden:
<ProductFormFeature>
<ProductFormFeatureType>09</ProductFormFeatureType>
<ProductFormFeatureValue>11</ProductFormFeatureValue>
</ProductFormFeature>
Die ONIX-Datei kann auch direkt im EPUB eingebettet und im OPF abgebildet werden:
<package xmlns="http://www.idpf.org/2007/opf"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:dcterms="http://purl.org/dc/terms/" version="3.0" xml:lang="en"
unique-identifier="bookid">
<metadata>
(…)
<link rel="onix-record" href="meta/onix.xml"/>
</metadata>
(…)
</package>
Diese Metadaten müssten Verlage in ihren Titelverwaltungssystemen pflegen. Ob ein System die Accessibility-Codes unterstützt bzw. wie teuer das Nachrüsten würde, kann man beim jeweiligen Anbieter leicht durch Besuche von Consultants oder im Rahmen mehrstündiger „Workshops“ erfahren. Einfacher scheint mir, direkt bei der EPUB-Konvertierung das ONIX um die entsprechenden Codes anzureichern, zumal in dieser Phase klar ist, welche Accessibility-Features der Titel enthält.
Status: Quo Vadis?
Mit XML hat man bereits die halbe Miete für barrierefreie E-Books. Dank der inhärenten Semantik und Struktur ist es beileibe keine Rocket Science, barrierefreie EPUBs zu machen. So unterstützt unser transpect-Framework das EPUB3-Format inklusive epub:type-Attributen, MathML, toc nav, landmarks nav und Page Lists. Beim Language Tagging lesen wir die in Formatvorlagen eingestellte Sprache aus. Dank CSSa werden typografische Informationen aus Formatüberschreibungen ebenfalls mitgeführt, wie z.B. css:font-style="italic". Anschließend kann aus dem CSS-Attribut ein semantisches em-Element in das HTML geschrieben werden.
Nichtsdestotrotz gibt es einige Dinge, für die wir bisher noch keine fertige Lösung haben. ARIA-Attribute würde ich außen vor lassen, da diese bei Apps mehr Sinn als bei E-Books machen. Wie weiter oben beschrieben, wiegt die inhaltliche Frage bei alternativen Inhalten schwerer als die technische. Was ONIX betrifft, so packen wir diese Daten zurzeit noch nicht in das EPUB-Paket. Da viele Metadatenworkflows auf ONIX basieren, wäre die Integration einfach. Hier ist nur die Frage offen, welche ONIX-Informationen sich der Verlag im EPUB wünscht und welche nicht.
Neben diesen lösbaren Aufgaben besteht das größte Hindernis für barrierefreie EPUBs aber immer noch in der weiten Verbreitung des EPUB2-Formats. Erst EPUB3 unterstützt semantische Attribute, MathML, landmarks nav und auch andere, nicht in diesem Beitrag behandelte Features wie Media Overlays oder CSS3 Speech. Auch wenn neuere Reader-Generationen nun immerhin in der Lage sind, EPUB3-Dateien zu öffnen ohne gleich den Dienst zu quittieren, bleiben noch genug alte Geräte auf dem Markt.
EPUB2 ist leider in puncto Barrierefreiheit hoffnungslos überholt und immer noch weit verbreitet. Die Hoffnung auf „ein EPUB für alle“ liegt daher noch in weiter Ferne. Dennoch ist es heute nicht schwer, Lesern (und Hörern) auch ein EPUB3 zur Verfügung stellen. Letztlich reicht dafür ein Download-Link in einer EPUB2-Datei aus. Mit XML als Grundlage, ist es keine schwarze Kunst ein barrierefreies EPUB3 zu erstellen. Barrierefreiheit ist nicht nur eine rein technische Angelegenheit, wie das Problem der Alternativtexte zeigt. Viele Verlage müssen nicht nur ihre Prozesse ändern, sondern auch die Sicht auf ihre Produkte. Heute gilt: Nicht nur die Typografie soll überzeugen, auch der Code muss gefallen.
Literatur
- Deltour, Romain: Born accessible EPUB. Let’s do it! in: XML Prague 2016. Conference Proceedings. Prag 2016, S. 1, URL: http://archive.xmlprague.cz/2016/files/xmlprague-2016-proceedings.pdf (Stand: 15.08.2016).
- IPDF: EPUB 3 Accessibility Guidelines, URL: https://idpf.github.io/a11y-guidelines/ (Stand: 15.08.2016).
- W3C: HTML5: Techniques for providing useful text alternatives. W3C Working Draft 23 October 2014, URL: https://www.w3.org/TR/2014/WD-html-alt-techniques-20141023/ (Stand: 15.08.2016).
- W3C: Accessible Rich Internet Applications (WAI-ARIA) 1.0. W3C Recommendation 20 March 2014, URL: https://www.w3.org/TR/wai-aria/ (Stand: 15.08.2016).
Dank
Vielen herzlichen Dank an Manuela Pohle von der DZB für die sachkundige Beratung zu Screenreadern.