Wenn über die Zukunft des Webs gesprochen wird, kommt man an „Web Components“ nicht vorbei. Dabei handelt es sich um eine Reihe von Entwürfen für kommende Standards des W3C, die es erlauben sollen, mit selbst definierten HTML-Tags wiederverwendbare Komponenten für das Web zu schaffen. Robin Berjon, Mitautor des HTML-Standards hat auf der XML Prague 2014 in einem Vortrag das Konzept vorgestellt. Von den Browser-Herstellern haben Google mit „Polymer Project“ und Mozilla mit „X-Tags“ eigene experimentelle Ansätze in diesem Jahr präsentiert.
Das Plugin-Problem
Web Components sollen dabei mehrere Probleme lösen, welche bisher die gemeinsame Verwendung von JavaScript-Plugins unterschiedlicher Provenienz in Webseiten erschwert haben. Ein Problem, das nicht zu gering zu achten ist, da moderne Webseiten sich heutzutage aus einem Fundus unterschiedlichster JavaScript-Bibliotheken bedienen. So gibt es bekannte JavaScript-Frameworks wie jQuery, das Dojo Toolkit und Sencha und unzählige kleine Anbieter, welche eigene Widgets für interaktive Formulare, Menüs, Galerien usw. anbieten. Allein zur Sichtung aller Bildergalerie-Widgets sollte man ein paar Tage Zeit einplanen. Eigene Plugins nicht zu vergessen, bei denen bestehende Alternativen ungeeignet erschienen. Alle verfolgen dabei eigene Ansätze, diese Plugins mit Webseiten bekannt zu machen und nicht selten kollidieren diese heterogenen Ansätze miteinander. Da keine etablierten Standards existieren, sind Inkompatibilitäten die Folge, welche den gemeinsamen Einsatz von unterschiedlichen Plugins erschweren.
Das Problem besteht darin, dass alle JavaScript-Plugins die HTML Dokumentstruktur, genauer gesagt das Document Object Model (DOM) manipulieren. Sie fügen Markup in den HTML Code ein bzw. generieren dieses automatisch. Hinzu kommen CSS-Regeln für das Styling und Objektnamen im JavaScript-Code. Eine friedliche Koexistenz ist ausgeschlossen, wenn im DOM Elemente mit den gleichen IDs vorhanden sind, CSS-Stile einander überschreiben oder globale JavaScript-Objekte gleich benannt sind.
Kapselung in XML
Im heutigen Web existiert bis dato kein allgemein gültiger Standard, um Funktionalitäten zu kapseln. XML-Geeks und XML-Geekettes haben es dank Namespaces deutlich einfacher, XML-Anwendungen wie etwa DocBook und SVG gemeinsam zu verwenden. Das Konzept dafür heißt XML Namespaces. Es ist einfach und elegant, trotzdem wird ihm gerne nachgesagt, es sei komplex und unverständlich. Es basiert darauf, dass jede XML Anwendung ihren eigenen Namespace besitzt, der durch eine URI und einen frei wählbaren Präfix repräsentiert wird. Die Namen der Elemente und Attribute erhalten diesen Präfix und lassen sich ohne Probleme miteinander verwenden. Solange man den Namespace explizit angibt, ist es sogar möglich, wenn auch nicht empfehlenswert, denselben Präfix für unterschiedliche Namespaces zu verwenden.
<?xml version="1.0" encoding="UTF-8"?>
<article version="5.0" xmlns="http://docbook.org/ns/docbook">
<title>SVG-Grafik in DocBook</title>
<mediaobject>
<imageobject>
<imagedata>
<svg:svg height="2cm" viewBox="0 0 400 400" width="4cm"
xmlns:svg="http://www.w3.org/2000/svg">
<svg:g style="fill-opacity:0.7; stroke:black;
stroke-width:0.1cm;">
<svg:circle cx="2cm" cy="2cm" r="100" style="fill:red;"
transform="translate(0,50)"/>
</svg:g>
</svg:svg>
</imagedata>
</imageobject>
</mediaobject>
</article>Aber das war nur ein kurzer Abstecher in die heile XML-Welt. Vergessen wir nicht: XML ist insbesondere wegen seines Namespace-Konzepts Web-Entwicklern nicht zumutbar, weshalb das W3C mit Web Components gleich vier Spezifikationen für die Kapselung von Funktionalität aus der Taufe gehoben hat:
- HTML Templates
- Shadow DOM
- Custom Elements
- HTML Imports
XML-Verarbeitung im Browser war schon immer ein Stiefkind, und es gab in der Vergangenheit zu viel Arroganz aus Richtung XML gegenüber Web-Entwicklern. So wurde z.B. der Wunsch nach korrigierenden, nachsichtigen Parsern für Wald- und Wiesen-Markup seitens der XML-Community, aber auch seitens der Browserhersteller, zu lange ignoriert, woraufhin dann eine Allianz aus eben diesen Browser-Herstellern und Web-Entwicklern sich entschloss, das Kind mit dem Bade auszuschütten und XML mit fast religiösem Eifer aus den meisten Web-Spezifikationen zu eliminieren.
HTML Templates
Templates braucht man in der Entwicklung als fertiges Gerüst, welches man schnell laden und mit Inhalten befüllen kann. Wenn man nicht alle neuen HTML-Elemente umständlich durch JavaScript generieren wollte, hat man bisher meist das Template in ein div-Element gekapselt, es mit einer ID versehen und mit CSS über display:none ausgeblendet. HTML-Templates basieren hingegen darauf, dass man in ein template-Tag weiteren Code einschleusen kann, der zwar vom Browser in den DOM geladen, aber nicht angezeigt wird.
<template id="user-image">
<div>
<img src="" alt="" style="border: 1px solid red">
</div>
</template>Mit JavaScript kann man nun über den DOM auf das Template zugreifen, beispielsweise um es an anderer Stelle dynamisch in das HTML-Dokument einzufügen. Dabei lässt sich auch auf CSS-Stile zurückgreifen, die in dem Template verwendet wurden.
var tmpl = document.getElementById('user-image').innerHTML;Der unbestreitbare Vorteil dieser Methode liegt darin, dass man nicht umständlich mit JavaScript dynamisch HTML-Elemente und CSS-Stile erzeugen muss, sondern diese einfach aus dem DOM in fertiger Form kopieren und an anderer Stelle wieder einfügen kann.
Custom Elements
Wenn man heutzutage mit JavaScript arbeitet, dann werden meist die HTML-Elemente div und span verwendet, um daran Funktionalität zu binden. Dieser Umstand liegt darin begründet, dass diese Elemente laut HTML-Spezifikation keine bestimmte Bedeutung haben, außer als Platzhalter für Block- oder Inline-Inhalte zu gelten. Dies hat aber auch den Nachteil, dass bei ambitionierteren JavaScript-Plugins schnell Heerscharen von div– und span-Elementen erzeugt werden, die den DOM bevölkern. Diese div– und span-Kaskaden sind für Quelltext-Leser zunächst wenig aussagekräftig und der W3C-Entwurf für sogenannte Custom Elements versucht hier einen deklarativeren Ausweg zu finden. Statt beispielsweise ein Profilbild in ein <div class="userimage"> zu kapseln, kann man nach der neuen Methode auch ein entsprechend benanntes Custom Element via JavaScript erzeugen:
var UserImage = document.registerElement('user-image');
document.body.appendChild(new UserImage());
Auf diese Weise wird ein Element namens user-image erzeugt, welches in den HTML body eingehängt wird. Damit ein HTML-Browser Custom Elements von bekannten und zukünftigen HTML-Elementen zu unterscheiden vermag, müssen diese ein Divis im Namen enthalten. Daher sind die Namen userimage oder user_image keine erlaubten Namen für Custom Elements.
Shadow DOM
Das esoterischste Konzept aus der Reihe der Web-Components-Spezifikationen ist das des Shadow DOM. Mit dem Shadow DOM wurde die Unterscheidung zum sogenannten Light DOM eingeführt. Der Light DOM ist der DOM, wie wir ihn bisher kennen: Elemente die in sich in der Baumstruktur des Light DOM befinden, lassen sich durch Skripte und Stile manipulieren. Alles, was sich jedoch innerhalb des Shadow DOM befindet, wird vor dem Zugriff von bestehenden CSS-Stylesheets und Skripten verborgen. Dergestalt ist es möglich, funktionale Grenzen im DOM zu etablieren und sicherzustellen, dass sich unterschiedliche JavaScript-Plugins nicht gegenseitig in die Quere kommen. Im folgenden wird exemplarisch ein Bild in den Shadow-DOM des div-Elements mit der ID userImage geladen.
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE html>
<html>
<head>
<title>Shadow DOM</title>
</head>
<body>
<div id="userImage"></div>
<script type="application/javascript">
/* <![CDATA[ */
var userImage = document.querySelector('#userImage')
shadow = userImage.createShadowRoot();
shadow.innerHTML = '<img src="user-image.jpg"/>';
/* ]]> */
</script>
</body>
</html>In Googles Chrome-Browser kann man sich den Inhalt des Shadow DOMs anzeigen lassen, wenn man die Option „Show user agent shadow DOM“ in den Einstellungen der Developer Tools aktiviert. Hier sieht man wie unterhalb des Wurzelelements des Shadow DOMs das Profilbild eingefügt wurde.
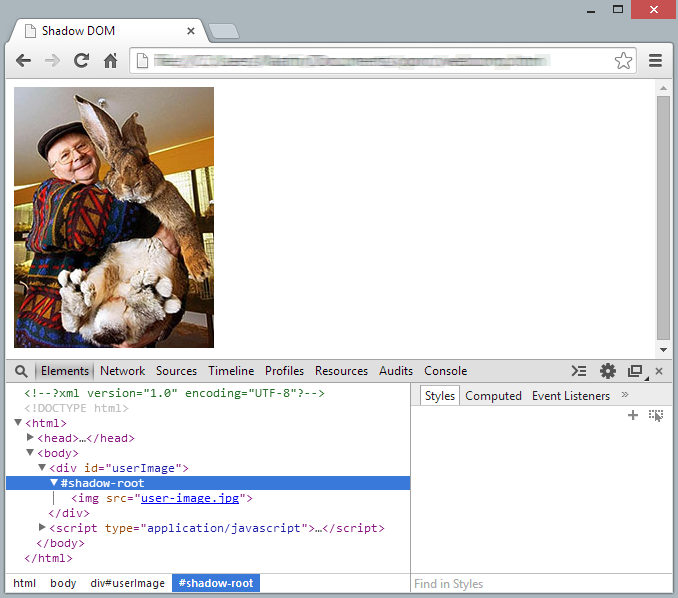
Unser Profilbild ist nun Bestandteil des Shadow DOM. Allerdings will man bei der Entwicklung eines Plugins nicht einfach alle Bestandteile im Shadow DOM verstecken, sondern nur bestimmte Bereiche. Andere Bereiche sollen durch Skripte oder CSS-Stile manipulierbar bleiben, um Interaktivität zu erlauben. Zu diesem Zweck wurde das neue content-Element eingeführt. Es erlaubt innerhalb des Shadow DOM Bereiche zu schaffen, die weiterhin von außen zugänglich bleiben.
In folgendem Beispiel wird zusätzlich ein content-Tag erzeugt, welches den Absatz innerhalb des div-Tags kapselt und ihn weiterhin für das Stylesheet zugänglich macht. Der Absatz unterhalb des Bildes verbleibt hingegen im Shadow DOM.
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE html>
<html>
<head>
<title>Shadow DOM
<style>p { color:red; font-size:2em }</style>
</head>
<body>
<div id="userImage">
<p id="name">mkraetke</p>
</div>
<script type="application/javascript">
/* <![CDATA[ */
var userImage = document.querySelector('#userImage')
shadow = userImage.createShadowRoot();
shadow.innerHTML = '<content></content><img src="user-image.jpg"/><p>description</p>';
/* ]]> */
</script>
</body>
</html>
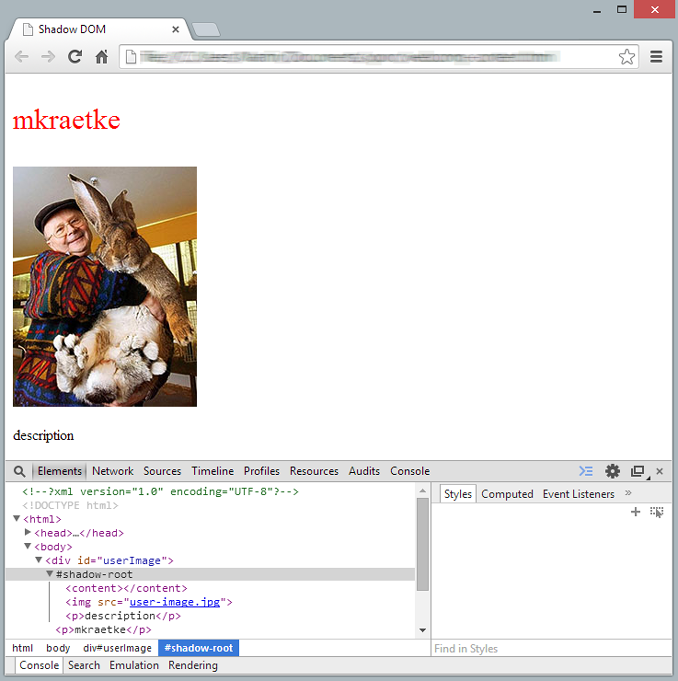
Wie man sieht, wird die im CSS-Stylesheet definierte Schriftfarbe und -größe auf den ersten, im content-Tag befindlichen Absatz angewendet. Mithin ist es möglich Darstellung und Inhalt zu trennen. Die Darstellung bleibt verborgen im Shadow DOM, während man einen definierten Inhaltsbereich weiterhin von außen manipulieren kann. Das Konzept des Shadow DOM ist damit vielleicht der wichtigste Schritt, um das eingangs erwähnte Plugin-Problem zu lösen.
HTML Imports
Auch wenn der HTML-Standard bisher einfache Lösungen für das Laden von Skripten, Stylesheets und Mediendateien vorsieht, war das Importieren von anderen HTML-Dokumenten bisher eher umständlich. Bislang existieren zwei Wege um HTML-Dokumente in eine Website einzuschleusen. Mit dem HTML-Tag iframe kann man externe HTML-Dokumente einbetten, allerdings werden diese in ein separates Fenster auf der Seite geladen und die Methode birgt vor allem große Schwierigkeiten, wenn man mit Skripting und CSS den iframe manipulieren möchte. Die andere Variante ist über AJAX via XMLHttpRequest möglich, aber es erscheint auch nicht sonderlich elegant JavaScript zu benützen, um HTML zu laden.
HTML Imports bieten nun eine Möglichkeit, mit HTML-Bordmitteln externe HTML-Dokumente in den HTML-Code der Website einzubetten. Der Import-Mechanismus ist schlicht: Man setzt in den Head-Bereich der Website ein link-Element mit dem Attribut rel="import" und gibt den Pfad zum HTML-Dokument an.
<link rel="import" href="document.html">Dabei muss beachtet werden, dass via HTML Imports referenzierte Ressourcen der Same-origin policy der Web-Browser unterliegen. Kurz gefasst, das referenzierte HTML-Dokument muss auf derselben Domain liegen oder via Cross-Origin-Resource-Sharing (CORS) zugänglich sein. Wer mehr über CORS erfahren möchte, dem möchte ich die Folien zum Datenvisualisierungs-Vortrag von Alex Oeser ans Herz legen. Dieser hat auf der Buchmesse 2013 dargestellt, wie es via CORS möglich ist, dynamisch Daten aus dem Web in E-Books zu laden und zu visualisieren.
Der Unterschied zwischen HTML Imports und einem iframe ist einfach. Im Gegensatz zu HTML Imports wird ein iframe unmittelbar im Browser dargestellt. HTML Imports werden vom Browser hingegen nur in den DOM geladen. Der Zweck von HTML Imports liegt vielmehr darin, dass man nachträglich mit JavaScript auf den DOM des importierten HTML-Dokuments zugreifen kann und diesen in sein Ausgangsdokument kopiert. Um den DOM eines HTML Imports in eine Variable zu packen, reicht diese JavaScript-Zeile aus.
var myHTMLimport = document.querySelector('link[rel="import"]').import;HTML Imports bieten damit einen einfachen Mechanismus, existierende Plugins innerhalb einer Website zu laden. Auch die im importierten HTML verwendeten Skripte und Stylesheets werden geladen. Nicht zuletzt werden auch verwendete HTML Imports im importierten HTML eingezogen (Sub-Imports). Auf diese Weise kann ein Plugin geladen werden, welches sich wiederum aus anderen Plugins zusammensetzt. HTML Imports vermögen es, HTML-Code, Skripte und CSS-Stylesheets in einem einzelnen HTML-Container zu bündeln und auszuliefern.
Web Components revisited
Eine Web Component fußt auf den vier vorgestellten Säulen. Eine Web Component ist nichts anderes als ein einfaches HTML-Dokument, welches ein HTML Template enthält, in dem das Grundgerüst der Web Component angelegt ist. Über JavaScript wird der Inhalt des HTML Templates in den Shadow DOM geladen und das Template als Custom Element unter einem bestimmten Namen bekannt gemacht. Zudem wird über JavaScript die gewünschte Funktionalität an das Custom Element gebunden. Zur Verwendung der Web Component genügt es, das HTML-Dokument via HTML Imports zu laden und das Custom Element in den HTML-Code der Website einzubetten. Google Maps als Web Component zu verwenden, kann dem Beispiel von Google folgend kaum einfacher sein. Man verwendet das Custom Element google-map und gibt Höhen- und Längengrad über dessen Attribute an:
<google-map latitude="37.77493" longitude="-122.41942"></google-map>Wo Licht ist …
Der Aufwand, ein JavaScript-Plugin als Web Component zu entwickeln ist zwar höher, als den Code einfach auf der grünen Wiese zur Verfügung zu stellen. Im Gegenzug erleichtert man seinen Nutzern die Einbettung und Verwendung seines Plugins. Die Verwendung des Shadow DOM stellt sicher, dass sich JavaScript-Code aus unterschiedlichen Federn nicht in die Quere kommt. Außerdem erhält man einen deutlich aufgeräumteren HTML-Quellcode und dank Custom Elements auch ein deklarativeres Markup.
… da ist auch Schatten
Wie Jeremy Keith jüngst in seinem Blog schrieb, erhalten Entwickler mit Web Components soviel Macht wie Browser-Hersteller. Während Browser-Hersteller und andere W3C-Mitglieder sich bei der Entwicklung von neuen HTML-Features an selbst auferlegte Richtlinien halten, trifft das nicht zwangsläufig auf jeden Web-Component-Entwickler zu. Das HTML5-video-Tag sieht beispielsweise einen Fallback-Mechanismus für ältere Browser vor. Ob eine Web Component dagegen einen Fallback enthält, liegt nur in den Händen des verantwortlichen Entwicklers. Falls die Sache schief läuft, kann auch die Darstellung der ganzen Seite durch eine Web Component in den Abgrund gerissen werden. Bisher werden Web Components übrigens nur von Google Chrome und Mozilla Firefox unterstützt. Diese kleine Seite gibt Aufschluss über den gegenwärtigen Stand des Browser-Supports von Web Components.
Es führt also kein Weg daran vorbei, verbindliche und validierbare Qualitätsstandards für Web Components zu entwickeln. Das wäre eine Aufgabe, die W3C und den Browser-Herstellern zukommen würde. Für die Entwicklung von Web Components empfiehlt Addy Osmani den FIRST-Grundsatz:
Keep it Focused, Independent, Reusable, Small and Testable
Auch die Barrierefreiheit von Web Components wird sich als Problem heraus kristallisieren. Während ein Screenreader um die Interpretation der bekannten HTML-Tags weiß, gilt das nicht für Web Components. Ob und wie eine Web Component ihre Inhalte an Screenreader ausliefert ist Sache des Entwicklers. Es gibt zwar eine noch recht junge W3C-Spezifikation für die Barrierefreiheit von Web-basierten Anwendungen, die unter dem Label Accessible Rich Internet Applications (ARIA) firmiert. Dort wird eine Semantik für die Funktionsweise und die Eigenschaften von Widgets festgelegt. Doch diese ARIA Attribute müssen von den Entwicklern bewusst in ihre Web Components eingebaut werden. Inwiefern sich Entwickler zukünftiger Web Components diese Semantik zu eigen machen, wird über den Erfolg oder Misserfolg dieses Standards entscheiden.
Web Components werden sich über kurz oder lang durchsetzen und eine Lingua franca für ein neues Ökosystem von Widgets und Plugins im Web bilden. Google und Mozilla haben mit Polymer und X-Tags bereits eigene Frameworks vorgestellt und unterstützen Web Components in ihren Browsern. Apple und Microsoft werden (in dieser Reihenfolge) sicher nachziehen.
Mit Web Components wird sich die Entwicklung des Webs grundlegend verändern. Den spezifizierten und standardisierten Elementen werden neue benutzerdefinierte Tags mit neuen Funktionalitäten zur Seite gestellt. Diese werden aus den verschiedensten Quellen entspringen, HTML um neue Features anreichern und nicht zuletzt zu neuen Problemen führen. Verbreitete und bewährte Web Components werden wiederum Eingang in den HTML-Standard finden. Dadurch wird die Weiterentwicklung des Webs stärker von den Web-Entwicklern selbst bestimmt werden – inklusive aller Vor- und Nachteile, die das mit sich bringt. Ob das Web mit Web Components nun einfacher, deklarativer und zugänglicher wird, ist ungewiss. Wir werden sehen.